




Dans l’article déjà cite, à la section « The Road From ANI to AGI – Why it is so hard », l’auteur cite trois exemples – les deux images que nous reprendrons ci-dessous, le chien et le chat, la lettre B – pour illustrer les difficultés que la recherche actuelle rencontre pour concevoir une intelligence similaire a la notre.
Ces mêmes exemples peuvent servir à faire la démonstration que ce niveau d’intelligence peut être répliqué de façon relativement simple.
Exemple 1 – Les deux images :
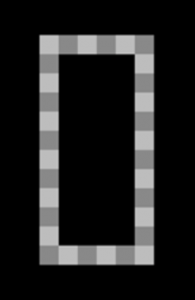

Image A Image B
1 – Identification ( le X de X+y=Z)
A est la représentation 2D d’une bande bicolore faite de carrés gris foncé et gris clair sur un rectangle noir. Ce constat est le résultat du croisement des champs conceptuels suivants :
- Représentation par image (dessins, photographies, peintures etc…)
- Formes (plan, bande, carré)
- Couleurs (noir, gris blanc)
Avec un logiciel approprie d’ ANI, l’ordinateur est tout à fait capable de cette description de premier niveau. Et il fera une description similaire de B. Or nous, nous ne nous contentons pas de cette réponse.
Nous voyons B comme une représentation en 3D. Pourquoi ?
2 – l’arbitrage (le Y de notre équation)
Existe-t-il dans notre base de données, des informations qui nous permettent de complémenter cette identification ?
La première observation que nous faisons, c’est que ces deux images sont totalement différentes l’une de l’autre. Cette différence entre A et B crée un conflit de représentation mentale, un déséquilibre qui doit trouver sa solution Ainsi, si certaines caractéristiques identifiées pour A valent aussi pour B, la ressemblance s’arrête là.
Nous allons donc enrichir notre exploration avec l’apport de nouveaux champs conceptuels :
- la représentation tridimensionnelle
- les formes tridimensionnelles
- les nuances d’ombre et de lumière
L’apport de ces champs conceptuels donne désormais une signification particulière à l’image. Nous « voyons » les cylindres, par exemple. Nous avons effectue une interprétation de deuxième niveau que notre ANI n’a pas faite. Cette identification est possible parce que nous avons appris ce qu’est une représentation dans l’espace, ce qu’est un volume etc.
Cet apport de nouvelles sources de données répond au besoin que nous avons de bien identifier B, et de le différencier de A. Et nous nous trouvons maintenant avec deux solutions possibles pour identifier B, L’une qui s’arrête à la perception première « B est une image 2D » qui n’est pas satisfaisante parce qu’elle n’exprime pas la différence d’avec A ; l’autre « B est l’image d’une représentation d’objets en 3D » qui est une identification de second niveau, mais qui répond au besoin de différencier A de B. Identification intelligente devrais-je dire.
Ce qui va déterminer le choix entre l’une et l’autre de ces identifications est une compétition darwinienne, merci Monsieur Dennet.
L’accès a une Human-like Intelligence passe donc nécessairement par la prise en compte de ces champs conceptuels, notion sur laquelle je reviendrai souvent.
3 – L’Expression, ou le Z de X+y=Z
Maintenant, la question est de savoir comment exprimer cette identification. Pour aller au plus simple, nous disons que nous avons deux images, l’une en 2D l’autre en 3D. Nous utilisons l’ellipse, une grande spécialité de notre mode d’expression. Mais si celle-ci présente l’avantage d’orienter immédiatement l’interprétation, elle a l’inconvénient de faire l’impasse sur tout ce qui a amené a cette identification, notamment le traitement de l’information lui-même, et la base de données qui l’accompagne. Si cela ne nous pose pas de problème, il n’en est pas de même pour la machine.
A suivre…